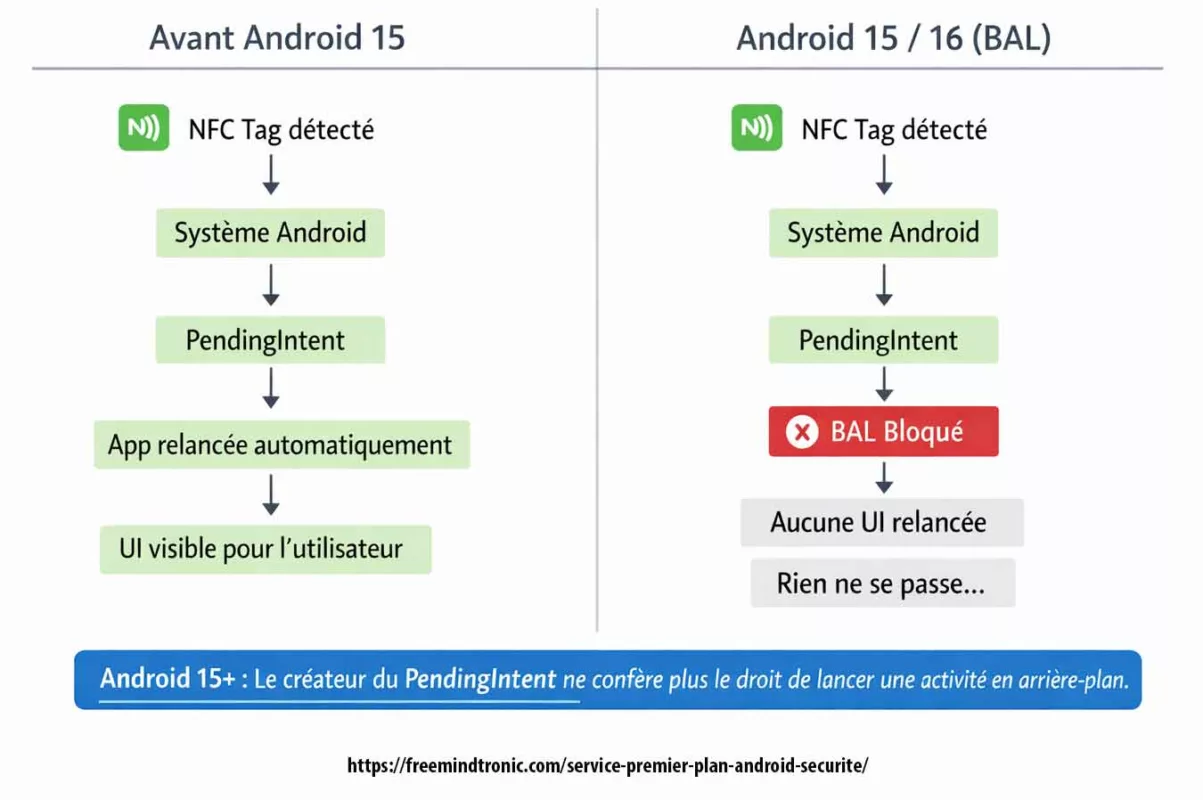
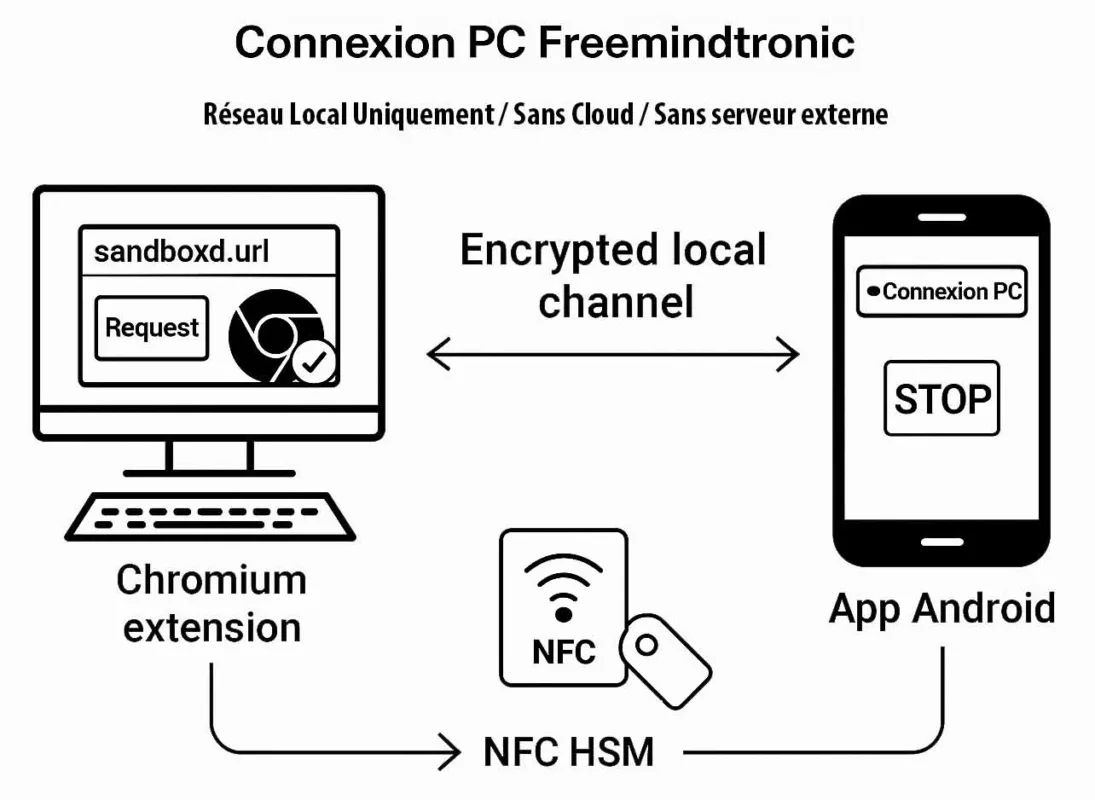
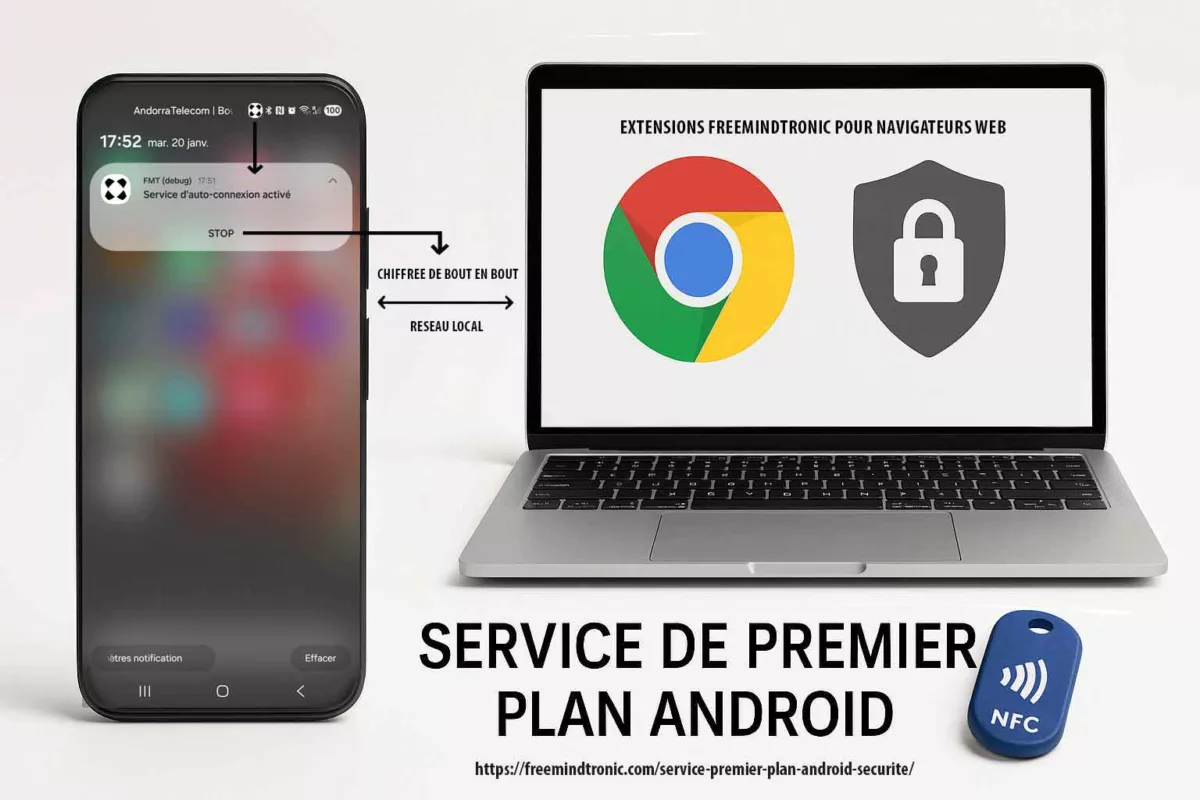
Contre espionnage numérique : points de décision matériels
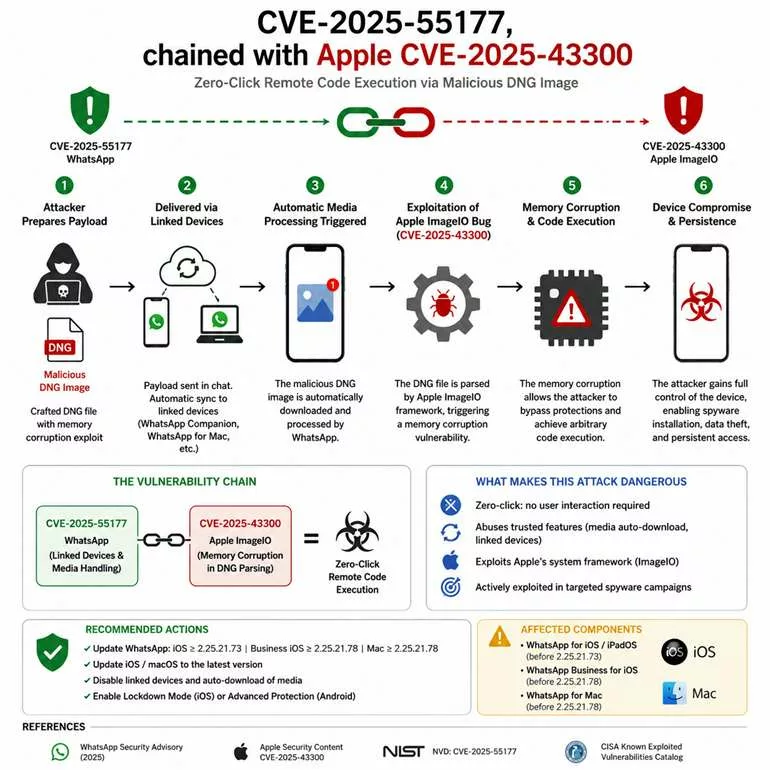
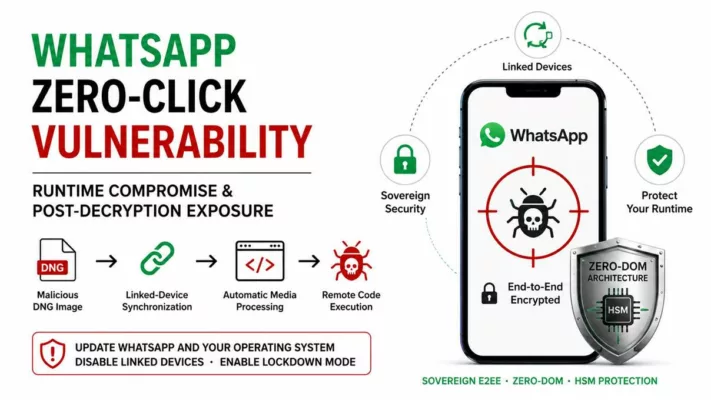
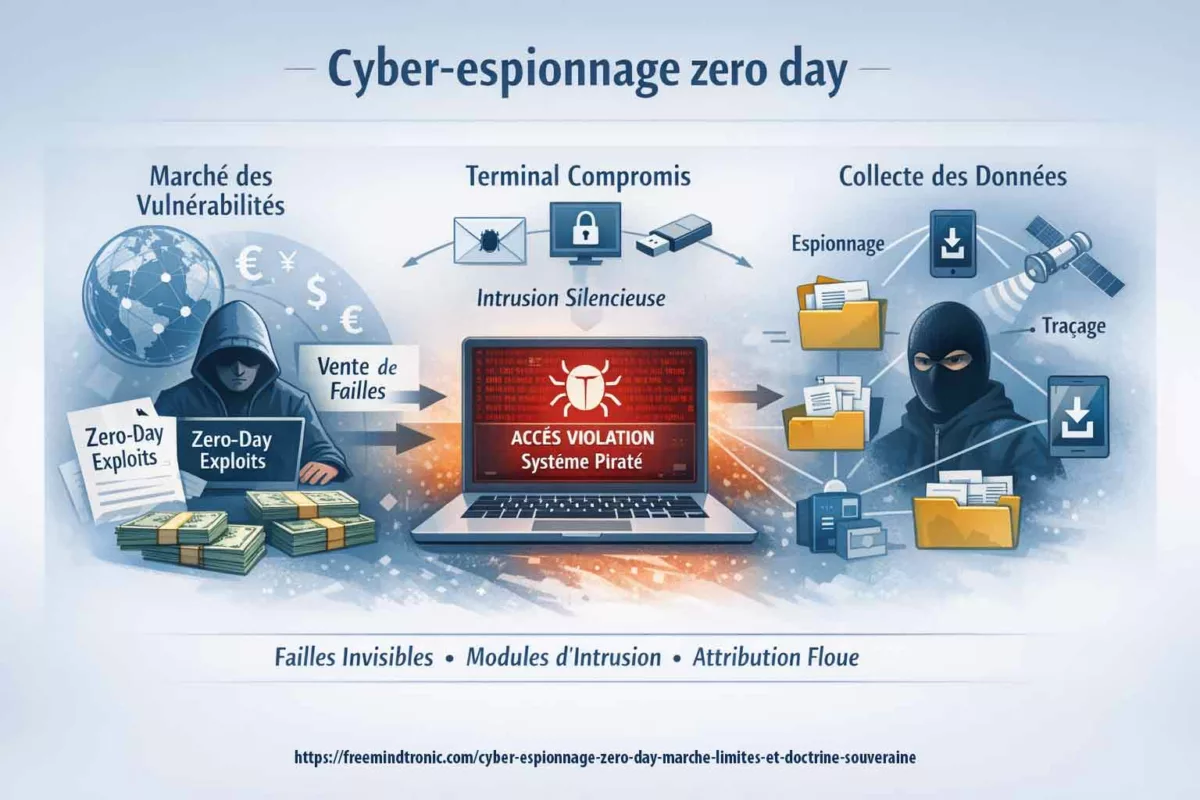
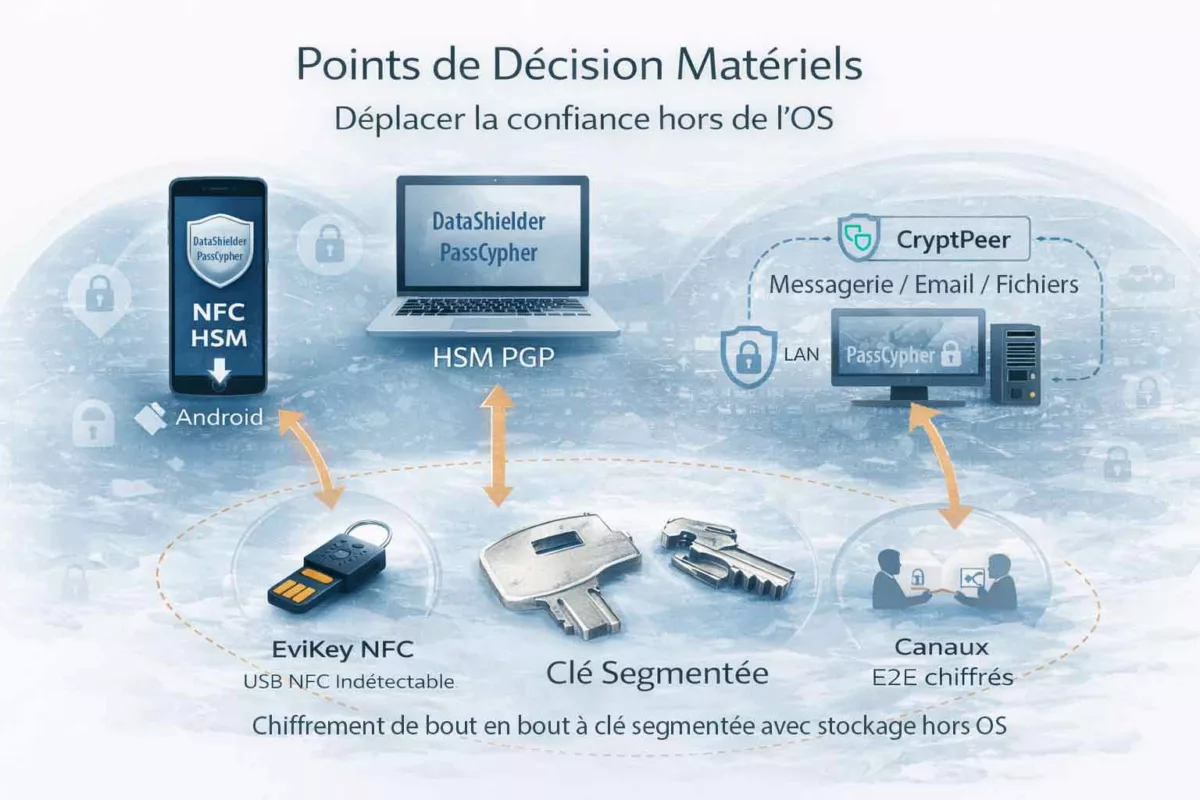
Lorsque la sécurité logicielle atteint ses limites, une autre approche devient nécessaire. Plutôt que de tenter de restaurer une confiance fragile, il s’agit de déplacer les décisions critiques hors de l’environnement compromis. Dans cette perspective, les points de décision matériels introduisent une séparation nette entre l’OS potentiellement hostile et les éléments qui ne doivent jamais lui être confiés, notamment en contexte de cyber espionnage zero day.
Autrement dit, l’objectif n’est pas de “rendre le terminal sain”, mais de préserver ce qui compte : secrets, identités, décisions et canaux. Pour cela, des dispositifs matériels (dont certains relèvent de logiques HSM selon les cas) et des mécanismes comme le chiffrement segmenté réduisent ce qu’un spyware ou un zero day peut capter, modifier ou automatiser. Repères institutionnels utiles pour cadrer cette doctrine : ENISA — Identity & Access Management · NIST — Hardware Security À ce stade, un point de méthode s’impose : ces mécanismes (contrôle d’accès, authentification à clé segmentée, politiques de confiance et exécution hors infrastructure) reposent sur des technologies protégées par un portefeuille de brevets déposés en France et étendus à l’international. Cette protection n’est pas un argument d’autorité ; en revanche, elle documente l’existence d’une architecture stabilisée et industrialisable, ce qui compte lorsque l’on raisonne en doctrine de contre-espionnage face au zero day.
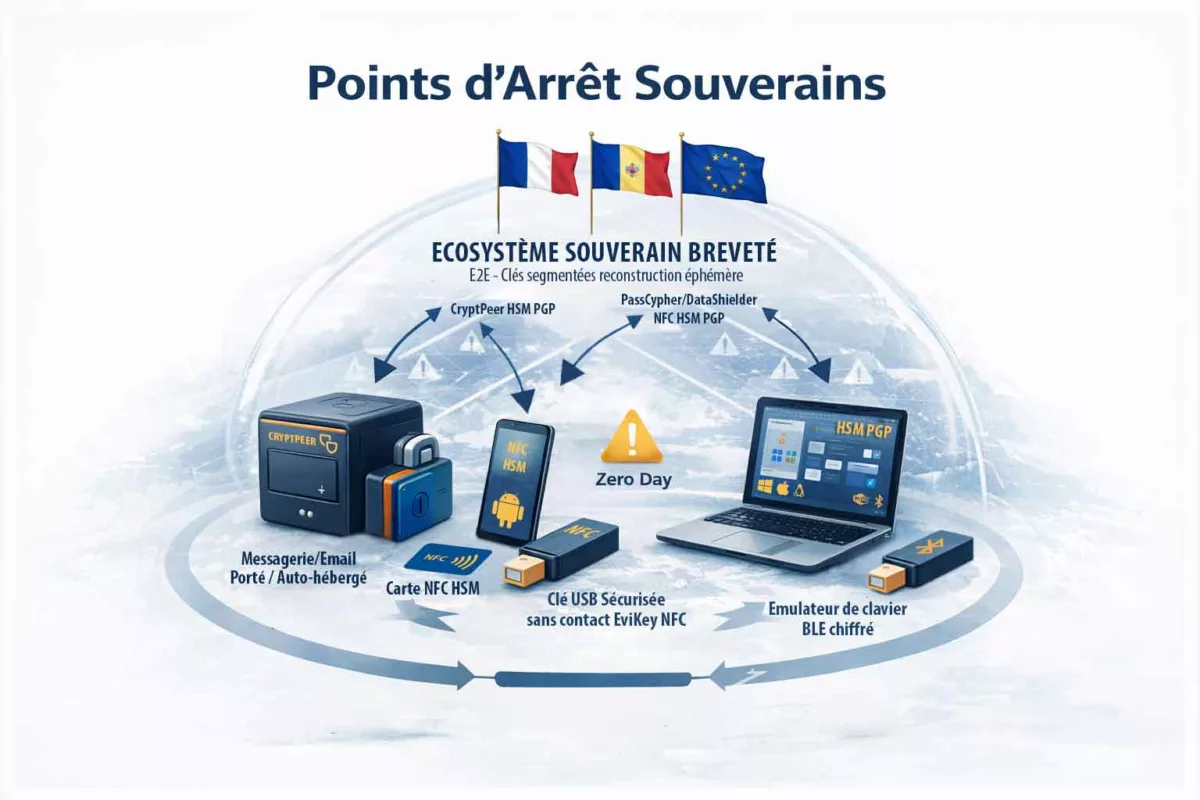
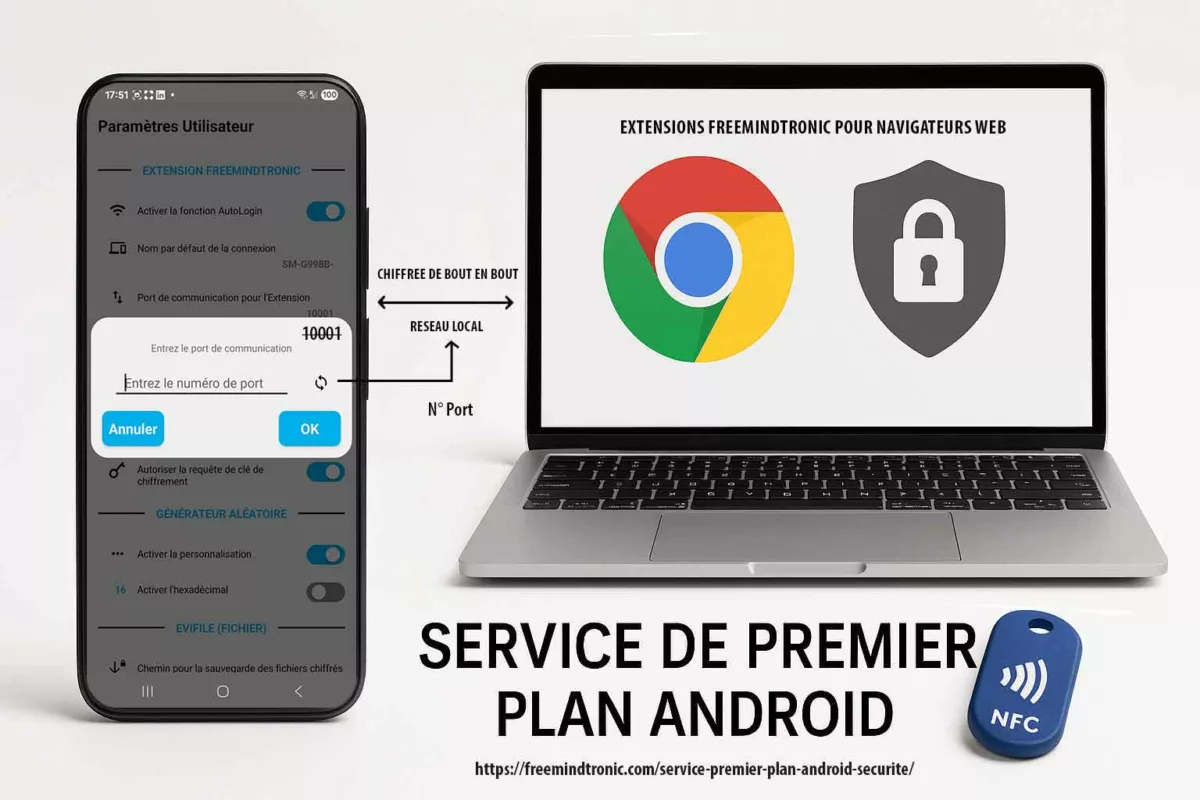
PassCypher NFC HSM et HSM PGP : secrets hors OS, clés segmentées et auto-login chiffré en mémoire volatile
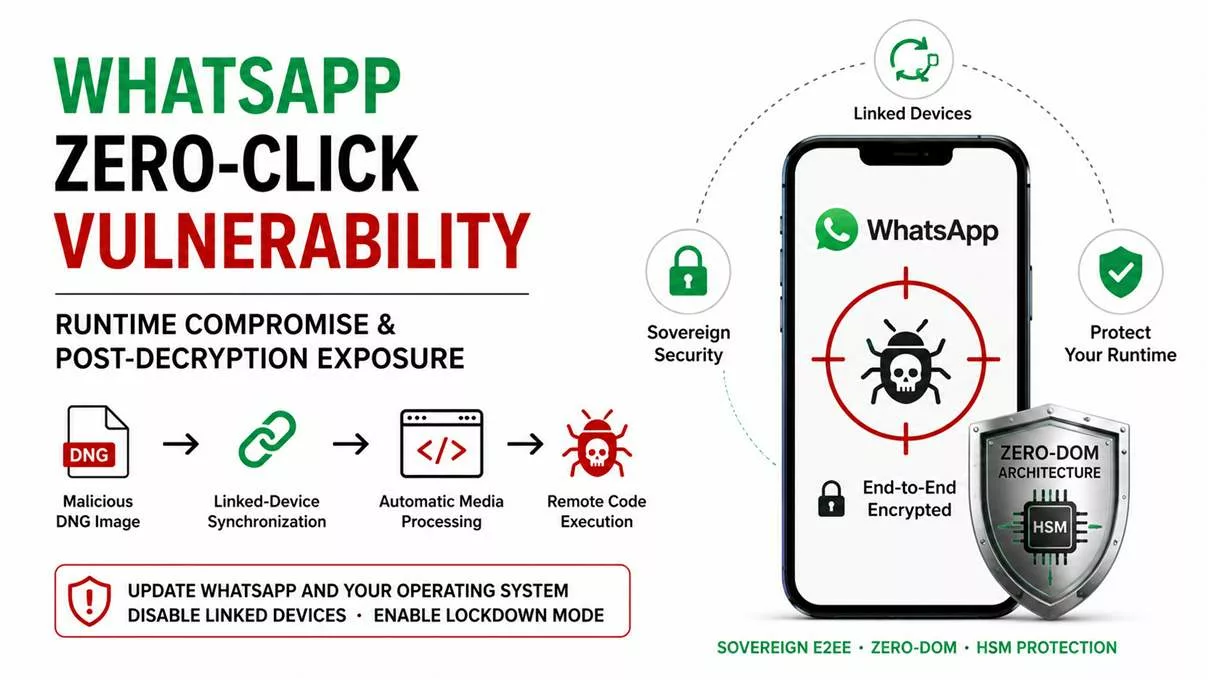
Dans un contexte de cyber espionnage zero day, la compromission d’un terminal ne vise pas seulement les fichiers. Elle vise surtout l’accès : identifiants, OTP, secrets de connexion, et automatismes d’authentification. Dès que ces secrets sont “manipulés” par l’OS, ils deviennent capturables, rejouables ou industrialisables par un implant. C’est précisément ce point que PassCypher cherche à neutraliser : déplacer la gestion des secrets hors du périmètre où l’OS peut mentir sur son état.
PassCypher NFC HSM : un point d’arrêt matériel pour la gestion de secrets
PassCypher NFC HSM repose sur des dispositifs NFC HSM sans contact pour stocker et délivrer des secrets sous contrôle matériel, sans serveur, sans base de données et sans compte utilisateur. Cette approche réduit la valeur d’un terminal compromis : même si l’attaquant observe l’interface, il ne dispose pas d’un stockage “OS” exploitable à grande échelle. En pratique, cela limite l’escalade post-compromission, car les secrets restent corrélés à une action volontaire et à une présence physique.
PassCypher HSM PGP : conteneurs chiffrés, clé segmentée et déchiffrement éphémère en RAM
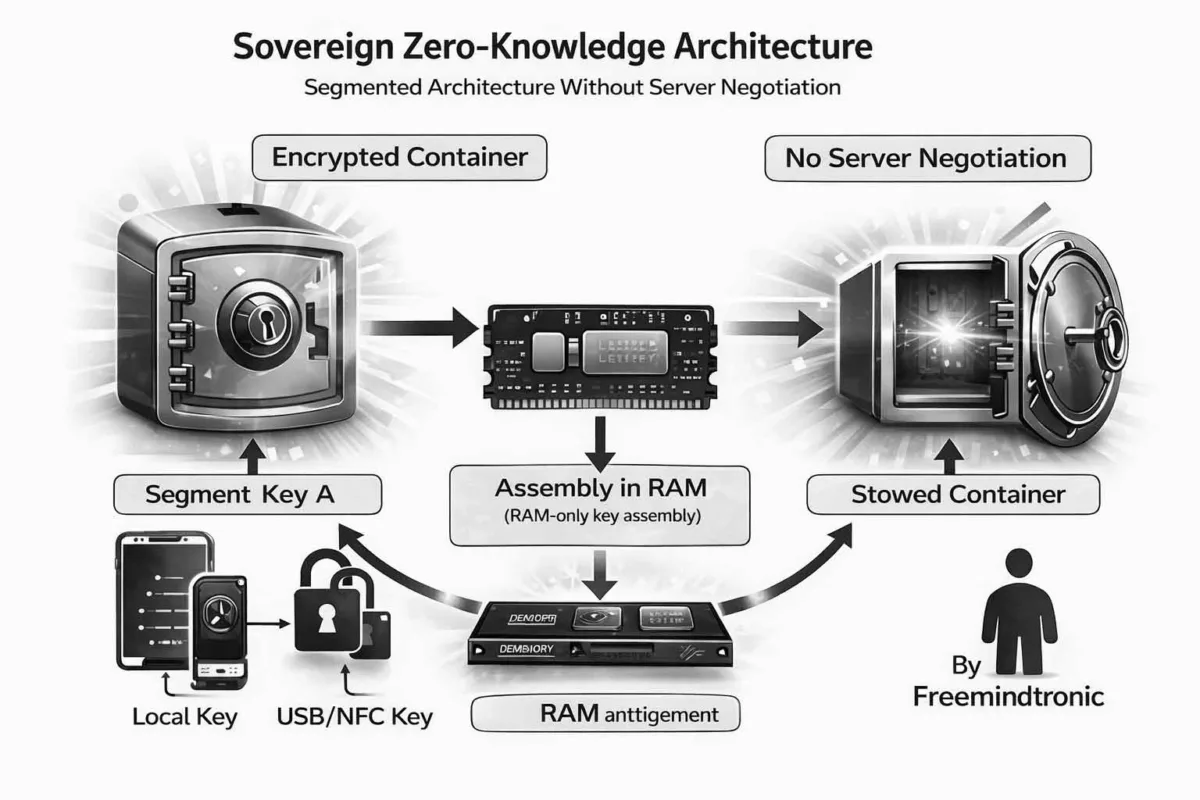
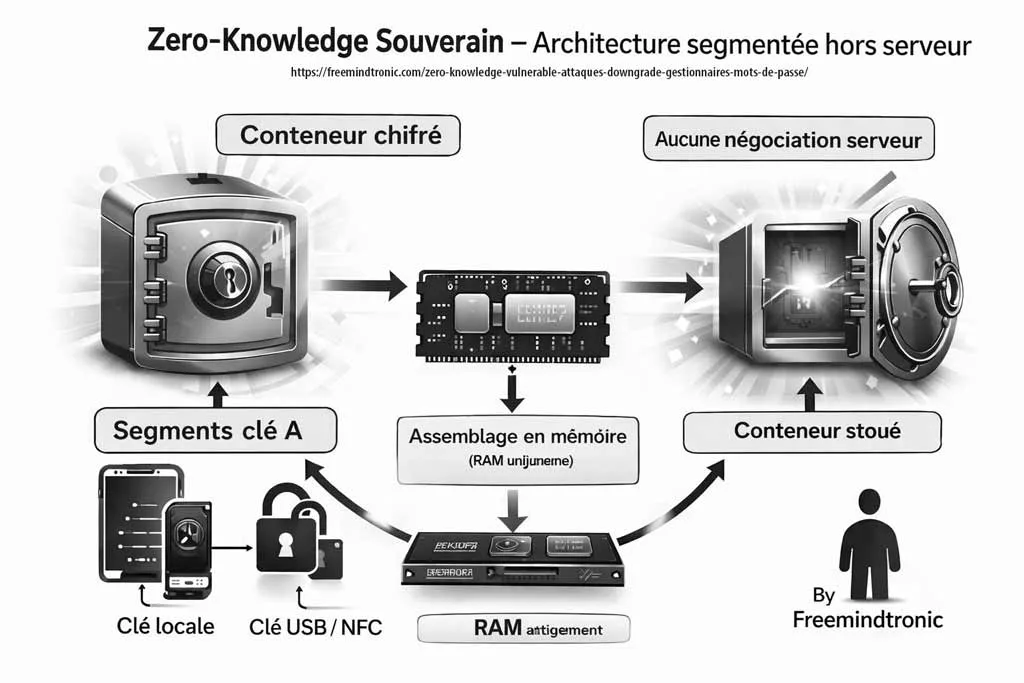
PassCypher HSM PGP étend cette logique en introduisant une automatisation complète via des conteneurs chiffrés (URL, identifiant, mot de passe, et paramètres associés). Les données de connexion sont chiffrées en AES-256 CBC PGP puis stockées sur un support choisi par l’utilisateur (USB, SSD, NAS, etc.). Lors de la connexion, le système lit le conteneur, le déchiffre brièvement en mémoire volatile, injecte les champs nécessaires, puis détruit immédiatement les données déchiffrées. L’objectif opérationnel est clair : empêcher qu’un malware récupère des identifiants par affichage, presse-papiers, ou persistance en clair. Le cœur de la défense repose sur une clé segmentée : un segment est conservé localement dans le navigateur, tandis qu’un second segment réside sur un support externe. Sans ce second segment, l’accès automatisé ne peut pas fonctionner. Autrement dit, même si un terminal est compromis, l’attaque ne peut pas industrialiser l’accès sans réunir les conditions matérielles attendues.
Pourquoi c’est pertinent face au cyber espionnage zero day
Dans cette chronique, PassCypher n’est pas présenté comme une “solution miracle”, mais comme un mécanisme de réduction de dégâts. Il vise à casser deux capacités clés du cyber espionnage moderne : la collecte silencieuse de secrets à grande échelle, et l’automatisation des connexions sur un terminal dont l’intégrité n’est plus attestable. Cela transforme la compromission en événement coûteux et moins reproductible, plutôt qu’en avantage durable. Sur le plan industriel et juridique, ces mécanismes s’inscrivent dans un portefeuille de brevets déposés en France et étendus à l’international, couvrant notamment des architectures de contrôle d’accès et d’authentification à clé segmentée. Références officielles : PassCypher NFC HSM · Fonctionnement PassCypher HSM PGP · Brevets internationaux Freemindtronic
DataShielder NFC HSM et HSM PGP : chiffrement segmenté, zéro persistance et anti-automatisation
DataShielder vise une zone rarement traitée correctement face au cyber espionnage zero day : le moment d’usage. Lorsque l’OS ne peut plus être attesté, la question n’est pas seulement de chiffrer, mais d’empêcher la captation des clés, la reproduction des accès et l’automatisation silencieuse des opérations. Dans ce cadre, l’approche DataShielder repose sur une logique centrale : la clé n’est jamais “posée” en entier là où un implant peut la copier.
DataShielder NFC HSM : gestionnaire de clés contactless, hors ligne et à clé segmentée
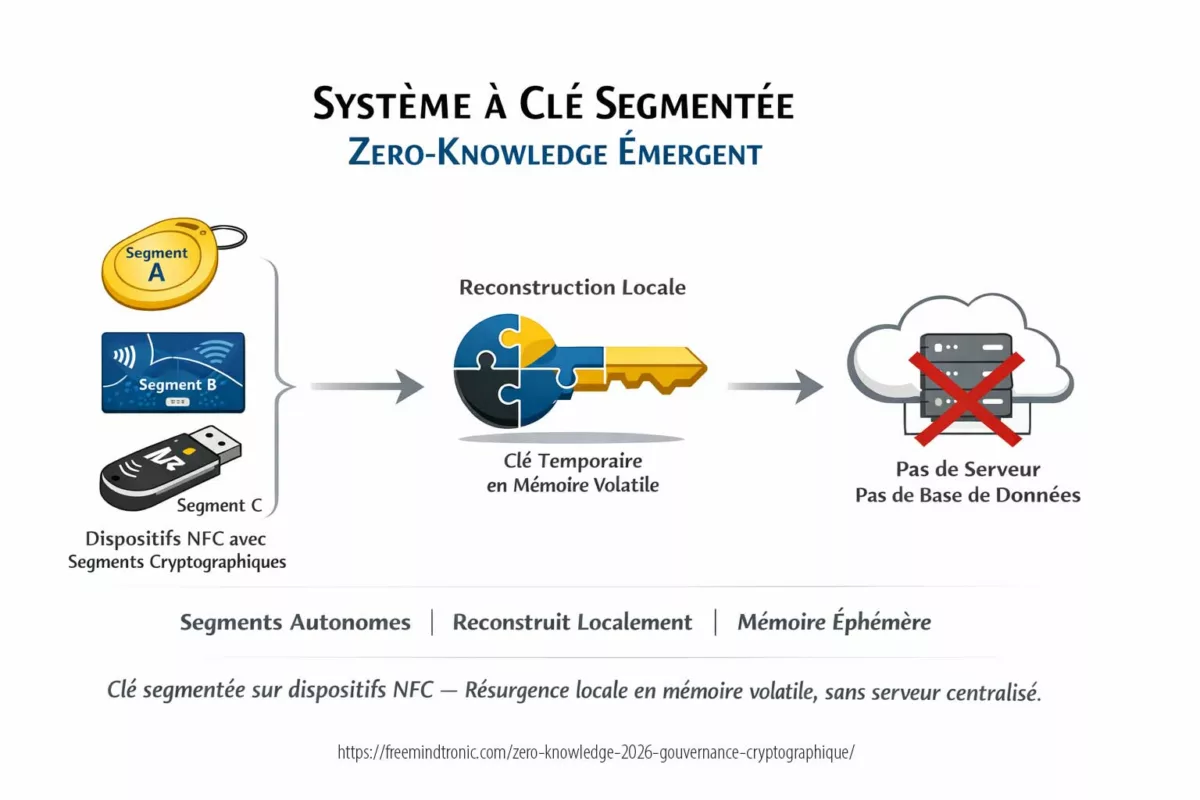
D’abord, DataShielder NFC HSM se positionne comme un gestionnaire de clés de chiffrement contactless conçu pour fonctionner en environnement zero-trust : entièrement hors ligne, sans serveur, sans cloud et sans base de données. La sécurité ne dépend donc pas d’une infrastructure, mais d’une architecture à clé segmentée et d’une reconstitution en mémoire volatile au moment strictement nécessaire, suivie d’un effacement après usage.
Ensuite, l’accès aux secrets peut être conditionné par des critères locaux : PIN, biométrie locale, QR, géozone, BSSID, empreinte de terminal et politiques d’accès. Autrement dit, même si une compromission logicielle contrôle l’interface, elle ne transforme pas automatiquement l’accès en capacité réutilisable, car l’opération dépend de conditions de confiance non triviales à rejouer.
Par ailleurs, l’intérêt anti-espionnage ne se limite pas au mobile. DataShielder NFC HSM peut aussi opérer dans des scénarios multi-équipements via des mécanismes de transfert contrôlé (proximité ou partage distant), ainsi que des intégrations orientées entreprise (BYOD/COPE/CYOD) lorsque la connectivité devient une vulnérabilité en soi.
DataShielder HSM PGP : chiffrement avancé côté navigateur, clé segmentée (2×256) et automatisation serverless
Ensuite, DataShielder HSM PGP étend cette doctrine au poste de travail via une logique “browser-first”. Le principe reste identique : une clé est segmentée en deux parties indépendantes. Un segment est conservé localement dans le navigateur, tandis que l’autre segment est stocké sur un support externe. La reconstitution ne se produit qu’au moment d’une opération cryptographique, en mémoire volatile, puis disparaît immédiatement après usage.
Cette segmentation produit un matériau de clé issu de deux segments de 256 bits. L’objectif opérationnel n’est pas d’annoncer un algorithme “AES 512”, mais d’augmenter la difficulté d’un attaquant : il doit compromettre deux emplacements distincts et réunir les segments au bon instant, ce qui réduit la valeur d’un implant zero day focalisé sur un seul environnement (OS ou navigateur).
Sur le plan cryptographique, la solution s’appuie sur AES-256 (mode CBC selon la documentation produit) et sur SHA-256 pour l’intégrité. De plus, la compatibilité OpenPGP et l’automatisation côté navigateur permettent des workflows interopérables, sans dépendance à un service tiers. Dans une chronique zero day, c’est un point clé : déplacer la confiance hors des plateformes, sans basculer vers un “cloud de sécurité” qui re-centralise le risque.
Enfin, l’architecture intègre EviEngine et DataShielder Engine pour automatiser des actions et gérer l’activation de fonctions sans serveurs ni bases de données, avec une logique de droits liée au matériel plutôt qu’à un compte utilisateur. Cette approche limite l’exposition aux identifiants, à la collecte et aux répertoires d’utilisateurs, qui deviennent fréquemment des cibles en espionnage.
Références officielles :
DataShielder NFC HSM — gestionnaire de clés contactless ·
DataShielder HSM PGP — chiffrement à clé segmentée ·
DataShielder Defense NFC HSM ·
Écosystème DataShielder.
Repère de conformité dual-use (cadre UE, sans interprétation) :
Règlement (UE) 2021/821 — biens à double usage
EviKey NFC : clé USB de sécurité, invisibilité matérielle et contrôle d’accès physique
EviKey NFC n’est ni un système de chiffrement ni un HSM. Il s’agit d’une clé USB de sécurité matérielle, conçue pour contrôler l’accès aux données par un mécanisme d’invisibilité physique et de verrouillage électronique autonome. Son rôle n’est pas de chiffrer l’information, mais d’empêcher qu’elle soit détectable, accessible ou exploitable tant que les conditions physiques et logiques ne sont pas réunies.
Lorsque l’EviKey est verrouillée, le support USB devient invisible pour tout ordinateur ou système hôte : aucun périphérique de stockage n’est détecté, aucun volume n’apparaît, et une exfiltration automatisée ne peut pas démarrer parce que le support n’existe pas du point de vue de l’OS. Cette propriété est directement pertinente face au cyber espionnage zero day, car elle réduit la capacité d’industrialisation de l’attaque sur un poste compromis.
Le déverrouillage repose sur une authentification NFC de proximité via un smartphone Android appairé et l’application Fullkey ou Fullkey Plus. Cette opération peut combiner appairage, code administrateur, code utilisateur ou PIN selon le niveau de sécurité défini. Tant que la séquence n’est pas validée, la clé demeure indétectable.
EviKey NFC n’embarque aucun chiffrement interne : l’utilisateur reste libre d’appliquer le chiffrement de son choix (BitLocker, Opal 2.0, PGP, chiffrement logiciel ou matériel externe). EviKey agit donc en amont, comme une barrière d’accès et de visibilité compatible avec tout système cryptographique.
Références officielles :
EviKey NFC — caractéristiques ·
EviKey NFC pour clés USB ·
EviKey USB — mode indétectable.
Cette invisibilité matérielle introduit un point d’arrêt non scriptable, ce qui constitue une rupture directe avec les chaînes d’attaque zero day automatisées.
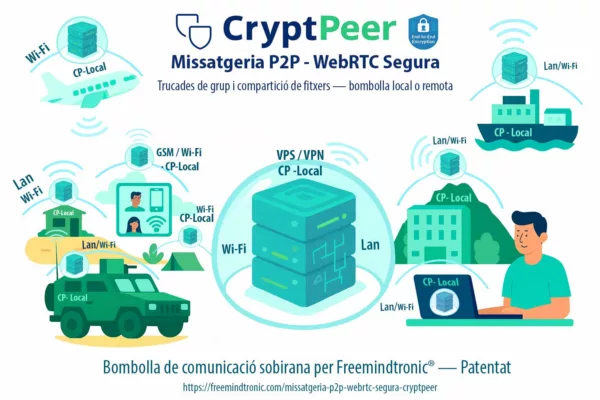
CryptPeer : communications chiffrées de bout en bout, collaboration et réduction des intermédiaires
CryptPeer couvre un périmètre plus large que le simple échange de messages. Il intègre une messagerie instantanée chiffrée de bout en bout, des appels audio et vidéo — y compris en mode groupe — ainsi que des mécanismes de transfert de fichiers sécurisés. L’ensemble est conçu pour fonctionner sans dépendre de plateformes centralisées exposant les flux, les contenus ou les métadonnées.
Le service inclut également un client de messagerie électronique chiffrée de bout en bout, compatible avec tous les systèmes acceptant OpenPGP (formats .asc). Le chiffrement est appliqué automatiquement côté expéditeur, avant tout transit réseau. Ainsi, même lorsque l’acheminement du courrier repose sur des serveurs tiers, le contenu demeure inaccessible aux intermédiaires.
En complément, CryptPeer propose un bloc-notes collaboratif chiffré de bout en bout. Cette fonctionnalité vise un angle souvent négligé du cyber espionnage : les espaces de travail partagés et les outils collaboratifs, qui constituent des gisements de données à forte valeur lorsqu’ils sont centralisés ou indexables.
Dans une chronique consacrée au cyber espionnage zero day, cet ensemble répond à une problématique précise : la compromission ne se limite pas au terminal. Elle s’étend aux canaux de communication, aux services de visioconférence, aux transferts de fichiers et aux plateformes collaboratives. En réduisant la dépendance à ces intermédiaires, CryptPeer diminue la surface exploitable par l’espionnage indirect, même lorsque l’environnement logiciel ne peut plus être pleinement attesté. Site web officiel :
CryptPeer® — Messagerie & Appels P2P Auto-Hébergés Chiffrés de Bout en Bout.
Lecture systémique face au cyber espionnage zero day
Dans ces modèles de contre-espionnage, la sécurité ne repose plus sur la confiance accordée aux plateformes, mais sur la maîtrise locale et matérielle des clés, des décisions et des canaux. Autrement dit, même en cas de compromission partielle du terminal, l’attaquant ne peut ni automatiser l’accès ni étendre l’attaque sans réunir des conditions hors OS. De cette manière, l’industrialisation du cyber espionnage zero day devient plus coûteuse, plus lente et plus risquée.
Point de vigilance éditorial — L’expression cyber espionnage zero day apparaît fréquemment, ce qui est cohérent avec le sujet central. Il ne s’agit pas de cannibalisation sémantique. La diversité des co-occurrences (perte d’attestation, compromission invisible, capacités d’intrusion, points d’arrêt hors OS) garantit l’équilibre éditorial sans sur-optimisation.
| Composant |
Point de décision déplacé |
Apport en contexte zero day |
| PassCypher (NFC HSM / HSM PGP) |
Accès aux identifiants et “moment de dévoilement” (clé segmentée + déchiffrement éphémère) |
Réduit la collecte de secrets et casse l’automatisation de la connexion sur un poste suspect |
| DataShielder (NFC HSM / HSM PGP) |
Gestion souveraine de clés segmentées + reconstruction en mémoire volatile + échanges hors serveur |
Réduit l’exfiltration de clés, limite l’effet d’un implant, et maintient des flux chiffrés en environnement à confiance dégradée |
| EviKey NFC |
Existence du support et accès aux données (invisibilité matérielle + contrôle NFC) |
Empêche la détection du support et bloque l’exfiltration automatisée tant que la clé reste verrouillée |
| CryptPeer |
Canaux de communication et collaboration (chiffrement de bout en bout + réduction des intermédiaires) |
Réduit l’exposition des contenus et des espaces de travail aux plateformes centralisées et à la collecte indirecte |
Synthèse
En pratique, ces points de décision ne “réparent” pas un terminal compromis. À l’inverse, ils déplacent la confiance vers des mécanismes hors OS (clé segmentée, exécution éphémère en mémoire volatile, support indétectable, canaux chiffrés de bout en bout), ce qui limite l’escalade et réduit l’automatisation malveillante.
Transition stratégiqueUne fois ces leviers posés, la question devient immédiatement opérationnelle : qui peut les déployer, dans quel cadre, et avec quelles contraintes de gouvernance ? Par conséquent, la section suivante clarifie les contre-mesures souveraines applicables face au cyber espionnage zero day, avant de décliner des cas d’usage (civil, double usage, régalien européen sous autorisation).