2025, Cyberculture
AI File Transfer Extraction: The Invisible Shift in Digital Contracts
Jun
Executive Summary
Update 22 july In 2025 : WeTransfer attempted to include a clause in its Terms of Service allowing the use of uploaded user files for AI model training. Withdrawn after public backlash, this clause unveiled a deeper dynamic: file transfers are becoming mechanisms of cognitive capture. Centralized platforms increasingly exploit transmitted content as algorithmic fuel—without informed consent.

2026 Cyber Doctrine Cyberculture
Individual Digital Sovereignty: Foundations, Global Tensions, and Proof by Design

2025 Cyber Doctrine Cyberculture
Uncodified UK constitution & digital sovereignty

2025 Cyber Doctrine Cyberculture
Constitution non codifiée du Royaume-Uni | souveraineté numérique & chiffrement
2025 Cyberculture EviLink
P2P WebRTC Secure Messaging — CryptPeer Direct Communication End to End Encryption

2025 Cyberculture Cybersecurity Digital Security EviLink
CryptPeer messagerie P2P WebRTC : appels directs chiffrés de bout en bout

2025 Cyber Doctrine Cyberculture
Souveraineté individuelle numérique : fondements et tensions globales

2025 Cyberculture
Louvre Security Weaknesses — ANSSI Audit Fallout

2025 Cyberculture
Audit ANSSI Louvre – Failles critiques et réponse souveraine PassCypher
Strategic Navigation Index
- Executive Summary
- Clause 6.3 – Legalized Appropriation
- CGU Comparison
- Geopolitical Reactions
- Sovereignty Acceleration – July 2025
- Global File Transfer Landscape
- Timeline of Algorithmic Drift
- Legal Semantics of ToS
- Sensitive File Typologies
- Cognitive AI Capture Statistics
- Algorithmic Contamination Cycle
- Sovereign Countermeasures
Key insights include:
Digital file transfers are no longer neutral mechanisms; they are increasingly transformed into algorithmic extraction vectors. Terms of Service, often written in opaque legalese, have evolved into covert infrastructures for AI training—turning user data into raw cognitive matter. Meanwhile, regulatory efforts struggle to keep pace, continually outflanked by the extraterritorial reach of foreign jurisdictions. In response, the European Union’s recent strategic initiatives—such as EuroStack and the proposed Buy European Act—signal a profound realignment of digital sovereignty. Yet, platform behavior diverges ever more from user expectations, and it becomes clear that only technical measures such as local encryption and isolated key custody can offer meaningful resistance to these systemic risks.
About the Author – Jacques Gascuel is the founder of Freemindtronic Andorra and inventor of patented sovereign technologies for serverless encryption. He operates in critical environments requiring offline, tamper-proof, auditable communications.
Clause 6.3 – Legalized Appropriation
WeTransfer’s 2025 attempt to impose a perpetual, transferable, sublicensable license on uploaded user files for AI purposes exposed the unchecked power platforms hold over digital content.
This move marked a watershed in the perception of user agreements. While the retraction of the clause followed intense public backlash, it revealed a broader strategy among digital service providers to legalize the repurposing of cognitive material for machine learning. Clause 6.3 was not a simple legal footnote—it was a blueprint for algorithmic appropriation masked under standard contract language.
“Worldwide, perpetual, transferable, sublicensable license for AI training and development.” – Extract from Clause 6.3 (Withdrawn)
Such phrasing illustrates the shift from service facilitation to cognitive extraction. By embedding rights for AI development, WeTransfer aligned with a growing trend in the tech industry: treating data not as a user right, but as a training resource. The episode served as a warning and highlighted the necessity for robust countermeasures, transparency standards, and sovereign alternatives that place user control above algorithmic interests.
CGU Comparison
A focused comparison of leading platforms reveals the systemic ambiguity and power imbalance in Terms of Service related to AI usage and data rights.
| Platform | Explicit AI Usage | Transferable License | Opt-Out Available |
|---|---|---|---|
| WeTransfer | Yes (Withdrawn) | Yes, perpetual | No |
| Dropbox | Yes via third parties | Yes, partial | Unclear |
| Google Drive | Algorithmic processing | Yes, functional | No |
Geopolitical Reactions
Sovereign concerns over AI data capture have sparked divergent responses across jurisdictions, highlighting gaps in enforcement and regulatory intent.
- European Union: AI Act passed in 2024, but lacks enforceable civil liability for AI misuse. Push toward EuroStack, Buy European Act, NIS2, and LPM reforms intensifies strategic sovereignty.
- United States: Pro-innovation stance. No federal constraints. Stargate program funds $500B in AI R&D. Cloud Act remains globally enforceable.
- UNESCO / United Nations: Ethical recommendations since 2021, yet no binding international legal framework.
Case Study: Microsoft under French Senate Scrutiny
On June 10, 2025, before the French Senate Commission (led by Simon Uzenat), Anton Carniaux (Director of Public and Legal Affairs, Microsoft France) testified under oath that Microsoft cannot guarantee French data hosted in the EU would be shielded from U.S. intelligence requests.
Pierre Lagarde (Microsoft Public Sector CTO) confirmed that since January 2025, while data is physically retained in the EU, the U.S. Cloud Act supersedes local encryption or contractual frameworks.
– Microsoft admits no guarantee data stays out of U.S. reach
– Cloud Act overrides encryption and contracts
– Transparency reports omit classified requests
Sovereignty Acceleration – July 2025
July 2025 brought a turning point in European digital sovereignty, with official declarations, industrial strategies, and new pressure on U.S. hyperscalers’ extraterritorial influence.
European Union Strategic Shift
- July 21 – Financial Times: EU proposes “Buy European Act” and EuroStack (€300B)
- New Tech Sovereignty Commissioner appointed; exclusion proposed for Amazon, Google, Microsoft from critical infrastructure contracts
Microsoft Senate Testimony (June 10 & July 21, 2025)
- Anton Carniaux, Microsoft France, acknowledges inability to block U.S. Cloud Act data access—even within EU
- Brussels Signal: France accused of “digital suicide” by outsourcing sensitive infrastructure to U.S. clouds
Microsoft Sovereign Cloud Response
- June 16 – Launch of “Microsoft Sovereign Public Cloud” with local controls, Bleu (Orange-Capgemini)
- KuppingerCole: positive move, but concerns over proprietary dependencies remain
– Cloud Act still overrides EU contractual frameworks
– Transparency reports exclude classified requests
– Strategic divergence between EU policy and U.S. platforms deepens
Global File Transfer Landscape
Comparison of major file transfer services reveals systemic vulnerabilities—ranging from unclear AI clauses to lack of encryption and non-European server locations.
| Service | Country | AI Clause / Risk | Reference / Link |
|---|---|---|---|
| TransferNow | 🇫🇷 France | Indirect algorithmic processing authorized | Terms PDF |
| Smash | 🇫🇷 France | Amazon S3 storage, potential AI processing | Official site |
| SwissTransfer | 🇨🇭 Switzerland | No AI, servers located in CH | Official site |
| Filemail | 🇳🇴 Norway | AI in Pro version, automated tracking | ToS |
| pCloud | 🇨🇭 Switzerland | Optional client-side encryption | Terms |
| Icedrive | 🇬🇧 UK | AI in enterprise version | GDPR |
| TeraBox | 🇯🇵 Japan | Native AI, tracking, advertising | Help Center |
| Zoho WorkDrive | 🇮🇳 India | OCR AI, auto-analysis | Under review |
| Send Anywhere | 🇰🇷 South Korea | Unclear risks, AI suggestions | Pending |
| BlueFiles | 🇫🇷 France | ANSSI-certified sovereignty | Pending |
Timeline of Algorithmic Drift
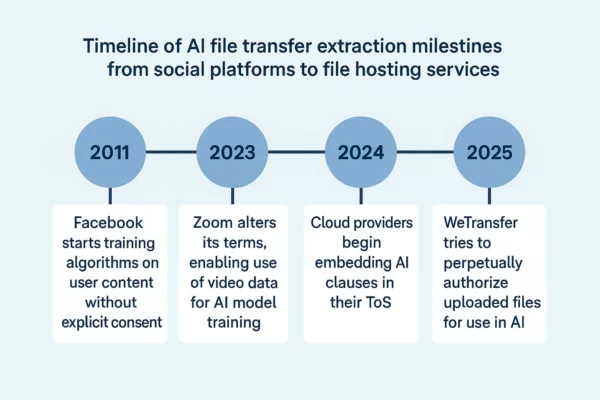
Tracing the evolution of AI file transfer extraction practices through key milestones, from early user content harvesting to the institutionalization of algorithmic appropriation.
The rise of AI file transfer extraction has not occurred overnight. It reflects a decade-long erosion of the boundary between user ownership and platform processing rights. In 2011, Facebook quietly began training algorithms on user-generated content without explicit consent, under the guise of service improvement. This pattern intensified in 2023 when Zoom inserted controversial clauses enabling the use of video streams for generative AI development.
By 2024, a wave of subtle yet systemic changes reshaped the Terms of Service of major cloud providers—embedding AI training clauses into legal fine print. These changes culminated in the 2025 WeTransfer debacle, where the overt Clause 6.3 aimed to codify perpetual AI training rights over all uploaded data, effectively legalizing cognitive content extraction at scale.
This drift illustrates a deeper structural shift: platforms no longer see uploaded files as inert data but as dynamic cognitive capital to be mined, modeled, and monetized. The user’s agency vanishes behind opaque contracts, while algorithmic models extract knowledge that cannot be retracted or traced.
Legal Semantics of ToS
Decoding how the legal language in Terms of Service enables hidden forms of AI file transfer extraction, revealing structural loopholes and algorithmic license laundering.
The Terms of Service (ToS) of digital platforms have become vehicles of silent appropriation. Their language—crafted for maximal legal elasticity—shields platforms from scrutiny while unlocking unprecedented access to user content. Phrases like “improving services” or “enhancing performance” conceal layers of cognitive harvesting by AI systems.
When a clause refers to a “perpetual, worldwide license,” it often translates to long-term rights of exploitation regardless of jurisdiction. The term “sublicensable” allows redistribution to third-party entities, including opaque AI training consortia. Meanwhile, catch-all terms like “content you provide” encompass everything from raw files to metadata, thus legalizing broad extraction pipelines.
This semantic engineering forms the linguistic backbone of AI file transfer extraction. It bypasses informed consent, turning each uploaded document into a potential data vector—where legality is retrofitted to platform ambitions. The visible contract diverges sharply from the underlying operational reality, revealing a growing rift between user expectations and AI data regimes.
Sensitive File Typologies
AI file transfer extraction does not treat all data equally. Administrative, biometric, professional, and judicial files are disproportionately targeted—each representing unique vectors of algorithmic appropriation.
Not all files carry the same cognitive weight. In the context of AI file transfer extraction, typology dictates vulnerability. Administrative files—containing national ID scans, tax records, or electoral data—offer structured, standardized templates ideal for training entity recognition systems. Similarly, biometric files such as passport scans or fingerprint data are exploited for facial recognition model reinforcement and biometric signature prediction.
Meanwhile, professional and contractual documents often include internal memos, business strategies, and technical schematics—unintentionally fueling AI agents trained on corporate decision-making and supply chain optimization. Judicial documents, ranging from affidavits to forensic reports, present a rare density of factual, narrative, and procedural data—perfectly suited for training legal decision engines.
Concretely, a leaked internal arbitration file from a multinational energy firm was reportedly used in 2024 to refine conflict resolution modules in a closed-source LLM deployed by a U.S. defense contractor. Elsewhere, a biometric file exfiltrated from a compromised passport office—later found in a 2025 training dataset for a commercial facial recognition suite—highlights the unintended consequences of lax file transfer governance.
– Pattern: Judicial files disproportionately present in anonymized training datasets
– Trend: Rising correlation between enterprise document formats and AI-captured syntax
– Vector: Embedded metadata used to refine prompt injection vulnerabilities
– Deploy DataShielder NFC HSM to localize file access with zero exposure
– Use PassCypher for contractual document integrity via hash verification
– Strip metadata before file transfers using sovereign scrubbers
Cognitive AI Capture Statistics
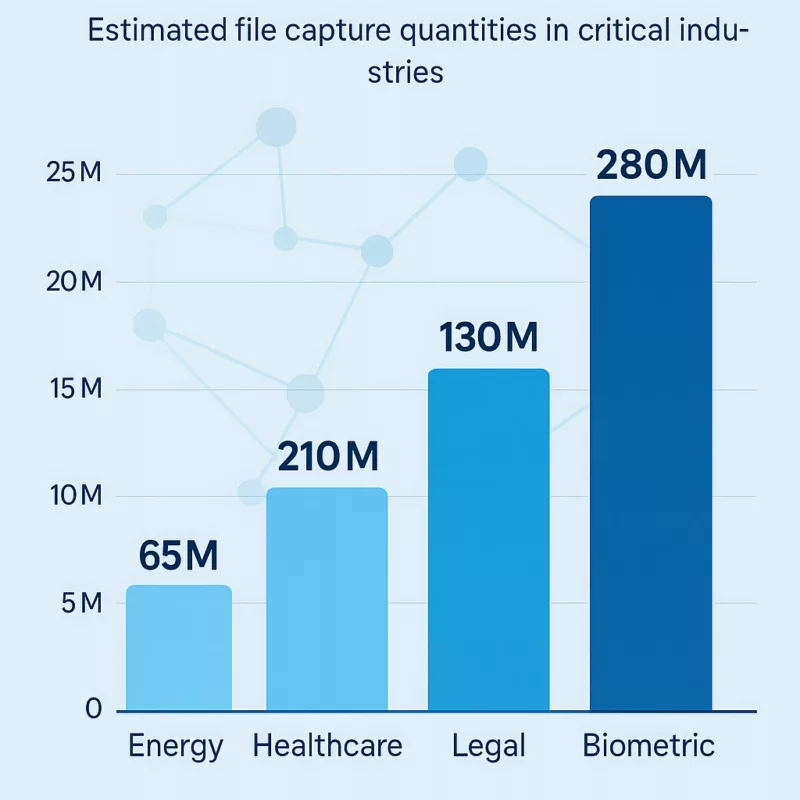
AI file capture now represents over 24% of datasets used for commercial model training. Sensitive sectors such as energy, healthcare, and legal services are disproportionately impacted.
According to the 2025 AI Dataset Integrity Consortium, approximately 1.4 billion documents extracted via public and semi-private channels were incorporated into model pretraining pipelines since 2023. Within these, legal records account for 16%, while biometric files comprise 11%. The healthcare sector—long presumed protected under HIPAA and GDPR—contributes nearly 19% of identifiable documents, largely through indirect metadata trails.
In practical terms, models trained on these datasets demonstrate elevated performance in tasks related to compliance prediction, medical diagnostics, and even behavioral inference. The economic value of such datasets is surging, with a recent valuation by QuantMinds placing them at €37.5 billion for 2025 alone.
Sector-specific analysis reveals that critical infrastructure sectors are not only data-rich but also structurally exposed: shared drives, collaborative platforms, and cross-border storage routes remain the most exploited vectors. As AI accelerates, the strategic imperative to regulate file-level provenance becomes a national security concern.
Algorithmic Contamination Cycle
Once ingested, contaminated files do not remain passive. They recursively alter the behavior of downstream AI models—embedding compromised logic into subsequent algorithmic layers.
The act of file ingestion by AI systems is not a neutral event. When a compromised or biased file enters a training dataset, it triggers a cascade: extracted knowledge reshapes not just that model’s predictions, but also its influence over future derivative models. This recursive pollution—a phenomenon we term the algorithmic contamination cycle—is now structurally embedded into most large-scale model pipelines.
Consider the case of predictive compliance engines used in fintech. A single misinterpreted regulatory memo, once embedded in pretraining, can result in systematic overflagging or underreporting—errors that multiply across integrations. The contamination spreads from LLMs to API endpoints, to user interfaces, and eventually to institutional decision-making.
Worse, this cycle resists remediation. Once a file has altered a model’s parameters, its influence is not easily extractable. Re-training or purging data offers no guarantee of cognitive rollback. Instead, AI architectures become epistemologically infected—reproducing the contamination across updates, patches, and forked deployments.
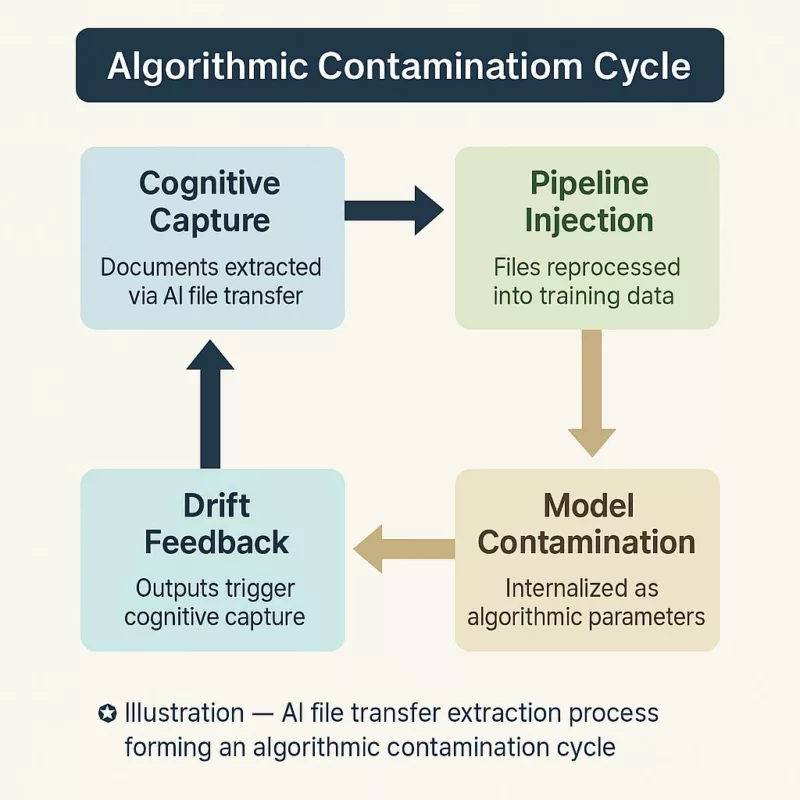
– Vector: Unmonitored AI pipelines reusing contaminated weights
– Pattern: Cascade of anomalies across decision support systems
– Risk: Institutional reliance on non-auditable model layers
– Isolate model training from operational environments
– Employ auditable training datasets using Freemindtronic-sealed archives
– Prevent contamination via air-gapped update mechanisms
Sovereign Countermeasures
From Legal Clauses to Operational Realities
Most mitigation attempts against cognitive AI capture remain declarative: consent forms, platform pledges, or regional hosting promises. These approaches fail under adversarial scrutiny. In contrast, Freemindtronic’s sovereign architecture introduces operational irreversibility: the data is cryptographically sealed, physically isolated, and strategically fragmented across user-controlled environments.
Discrepancies Between Clauses and Actual Exploitation
Recent examples underscore this fragility. In 2025, WeTransfer attempted to introduce a clause enabling AI training on uploaded files. Though officially retracted, the very proposal confirmed how CGUs can be weaponized as silent appropriation instruments. Similarly, SoundCloud’s terms in early 2024 briefly allowed uploaded content to be used for AI development, before the platform clarified its scope under pressure from the creator community.
Timeline: The WeTransfer Clause 6.3 Incident
- June 2025: WeTransfer updates Clause 6.3 to include rights “including to improve performance of machine learning models” — set to take effect on August 8, 2025.
- July 14, 2025: The clause is flagged publicly on Reddit (source), triggering concern across creative communities.
- July 15, 2025: WeTransfer issues a public clarification that it “does not and will not use files for AI training” (official statement).
- July 16, 2025: Revised ToS removes the AI clause entirely (coverage).
First alarm was raised by professionals in Reddit’s r/editors thread, quickly echoed by Ashley Lynch and other creatives on X and LinkedIn. This incident highlights the time-lag between clause deployment and retraction, and the necessity for vigilant watchdog networks.
Such episodes highlight a critical dynamic: CGUs operate in the realm of legal possibility, but their enforcement—or the lack thereof—remains opaque. Unless independently audited, there is no verifiable mechanism proving that a clause is not operationalized. As whistleblowers and open-source investigators gain traction, platforms are pressured to retract or justify vague clauses. However, between declared terms and algorithmic pipelines, a sovereignty vacuum persists.
Devices such as DataShielder NFC HSM render files unreadable unless decrypted via local authentication, without server mediation or telemetry leakage. Meanwhile, PassCypher validates document provenance and integrity offline, resisting both exfiltration and prompt injection risks.
These tools do not simply protect—they prevent transformation. Without access to raw cleartext or embedded metadata, AI systems cannot reconfigure input into modelable vectors. The result is strategic opacity: a file exists, but remains invisible to cognitive systems. Sovereignty is no longer abstract; it becomes executable.
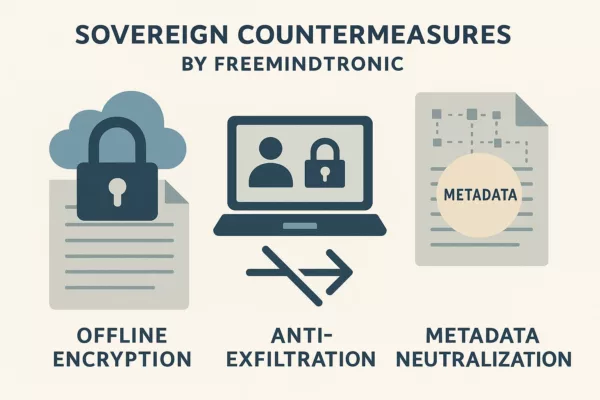
🔗 Related to:
– Chronicle: The Rise of AI-Assisted Phishing
– Note: Exploiting Offline NFC Vaults for Counter-AI Defense
– Publication: Securing Supply Chains Through Sovereign Cryptography
⮞ Sovereign Use Case | Resilience with Freemindtronic
In a cross-border legal proceeding involving sensitive EU arbitration documents, Freemindtronic’s DataShielder NFC HSM was deployed to encrypt and locally isolate the files. This measure thwarted exfiltration attempts even amid partial system compromise—demonstrating operational sovereignty and algorithmic resistance in practice.